
I have been completing some maintenance in my lab recently. I always like to try and keep my nested environments as up to date as possible, which, unfortunately has recently caught me off guard. What do I mean by this? Well long story shot I was caught in the “vCetner Server Back-in-time release upgrade restrictions”, I wanted to upgrade my nested environments, of which my HCX Cloud destination is one of, to vSphere 8 but my vSphere 7 installation was to new so this prevented said upgrade. You can read further details about this in the following VMware KB article.
After some time passed, vCenter 8.0b was released and I was in a position to bring my HCX nested lab up to date. Once NSX and vSphere were patched, I fired up HCX to confirm all was still well and noticed a new upgrade there too, HCX 4.6. The release note’s revealed a new feature that I had to test, migration retry!
Although this can seem like a small thing to be added to the product, I think that it brings some great benefits. Lets say you have a mobility group configured and one of those VM’s fails in the at a point in the process. This could be for any number of reasons, but the example I have tested this with in my lab is down to available storage on the Cloud destination. Well in fact that was the initial plan, the blog post evolves as it was written/tested and I used a slightly different method to cause a failure within HCX.
I went ahead and created a mobility group, with just a single VM in there ready to migrate to the HCX Cloud destination.
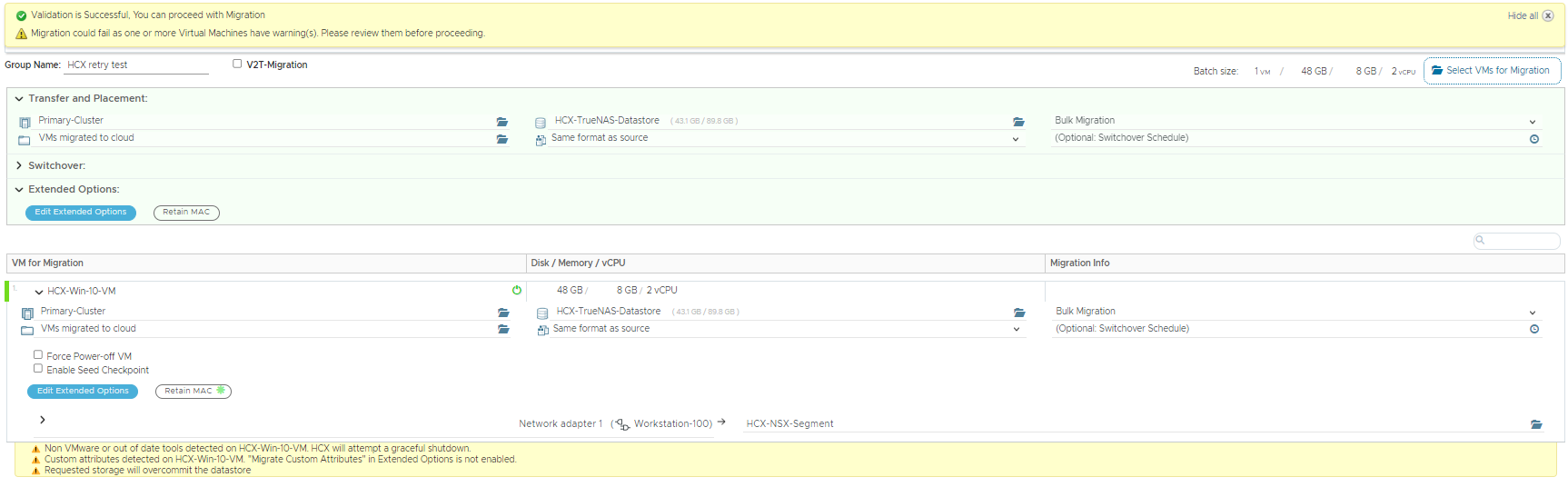
Currently that VM consumes 38.2GB of storage on the source site.
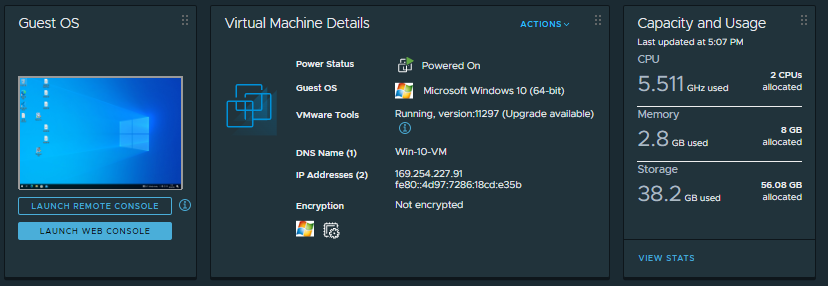
There is 43.11GB of free storage in the HCX Cloud destination, so as we saw above the validation task completes without any errors, so I start the replication task, the base sync has now started.
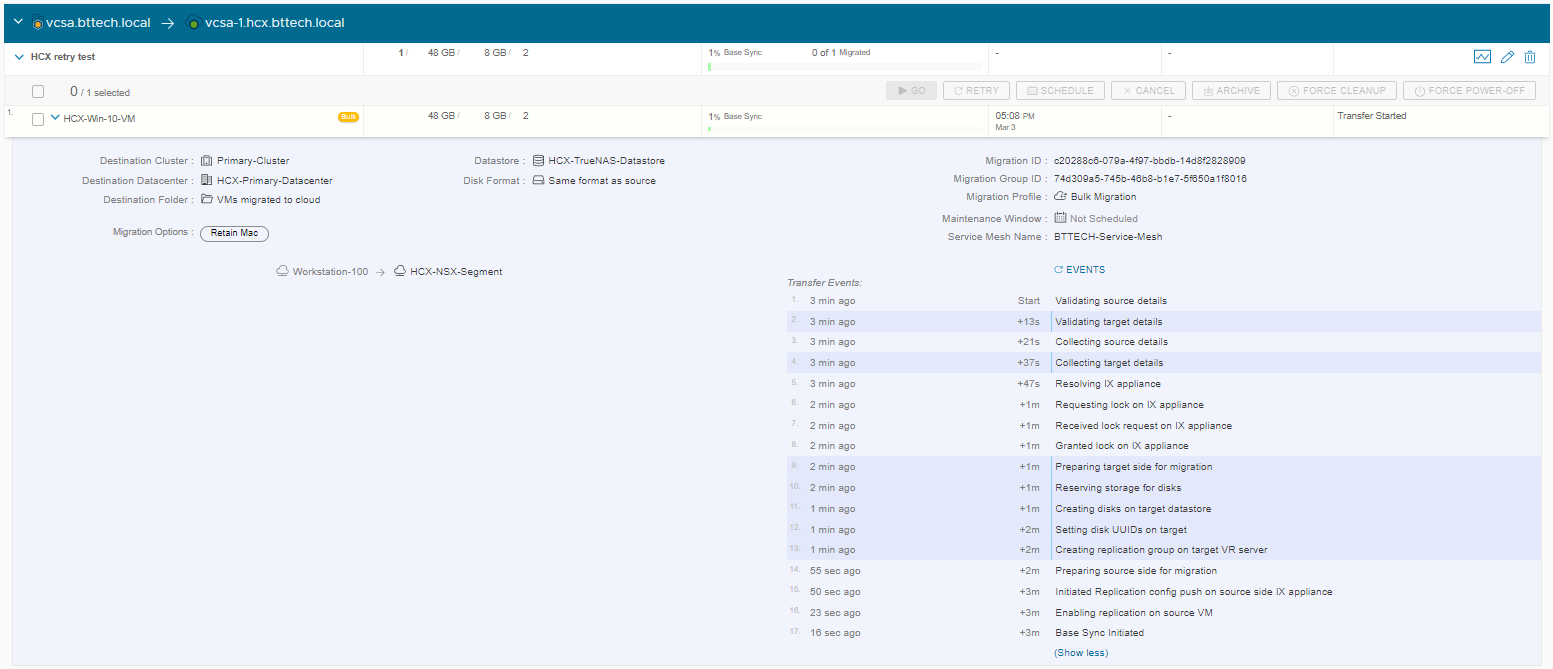
The quickest way I could think to simulate a full datastore after the migration task has started replicating data was to create a dummy VM in the datastore using a thick provisioned disk to consume the space on the datastore.
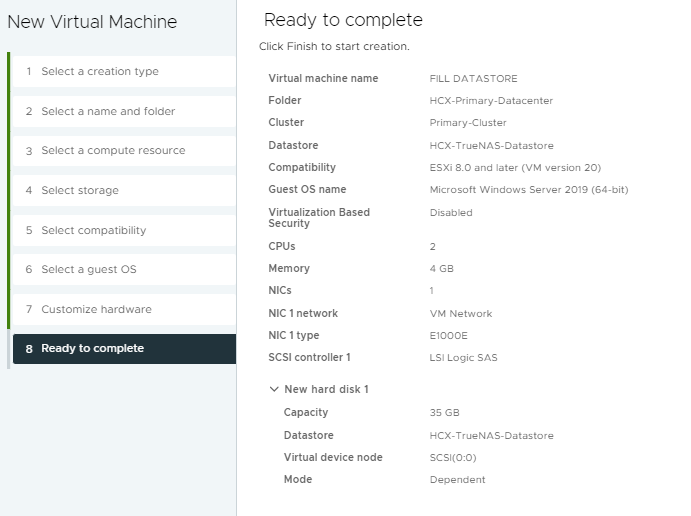
This then very quickly filled a lot of space on the datastore leaving me with no where near enough storage to complete the replication task.
Now it was just a waiting game to let the data replication fail. The datastore fill up fairly quickly as would be expected, the failure of the task in HCX took a little while though. In fact all it seemed to do to start with was increase the estimated completion time. So I decided I had to come up with a slightly different way to cause a failure within HCX – odd isn’t it really trying to force a failure, I cancelled the current migration task and freed up the space in the datastore. Ironically, I could have used the cancelled task as well to test the retry option :). As there could be a scenario for example where you have cancelled a migration task that is currently running, you may want to run this at a different time for example. The retry function would be perfect for this as well.
I decided to try and pair/register HCX with vCenter in the destination site using a different SSO account, one that didn’t have the ability to power on a VM, surely this would cause a failure!?
I set up a new mobility group with a much smaller VM to speed up the test process.
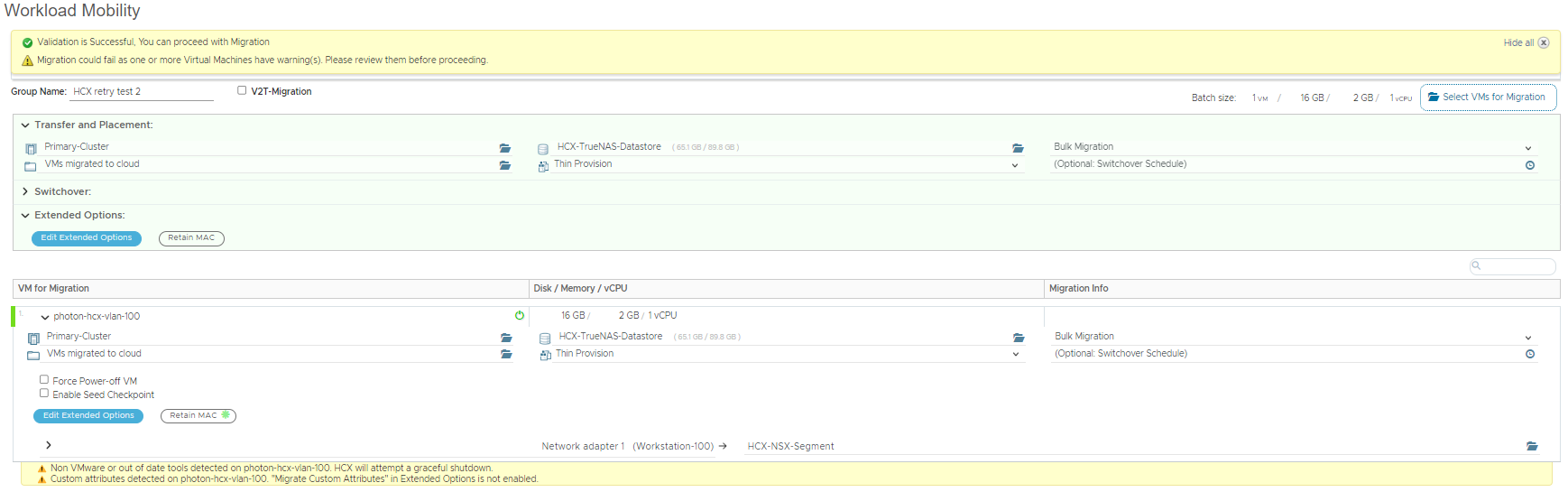
After a few minutes, I got the result I wanted, there was a switchover error as the VM couldn’t be powered on.
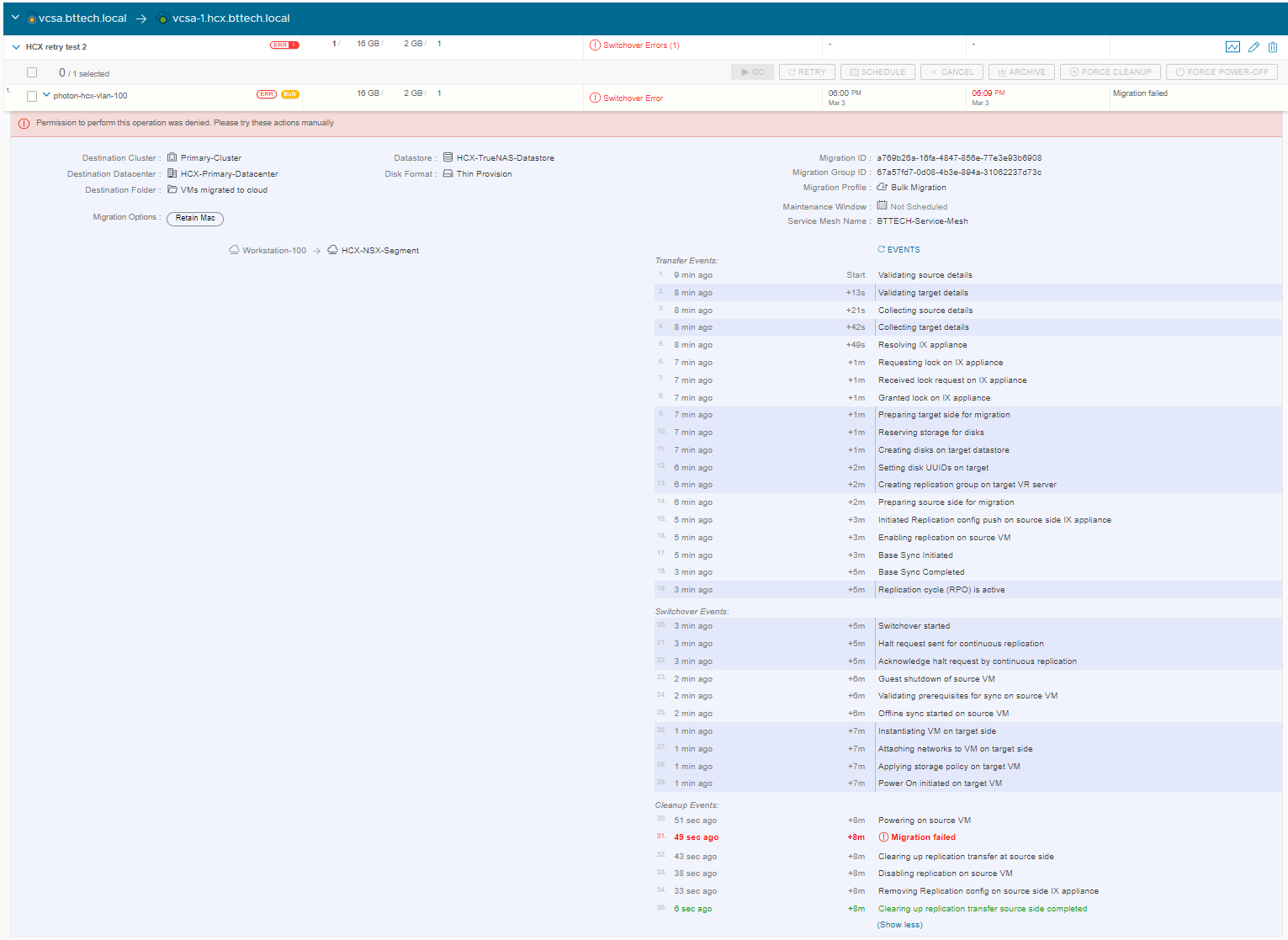
We can see on the source site the VM with a HCX Bulk migration task tagged against it showing as failed as well.

I have gone ahead and fixed the issue that cause the failure, and the service account can now power on VM’s. You would before now have to re-create the mobility group within HCX, reselecting all the parameters you require for the migration, destination compute, datastore, network details etc. This is where the new retry feature can save up some time and help speed up this process. After selecting the VM within the mobility group we have the option to retry as shown below.

After selecting this we simply need to confirm the retry operation. This then restarts the process with the same configuration parameters that you input before hand.
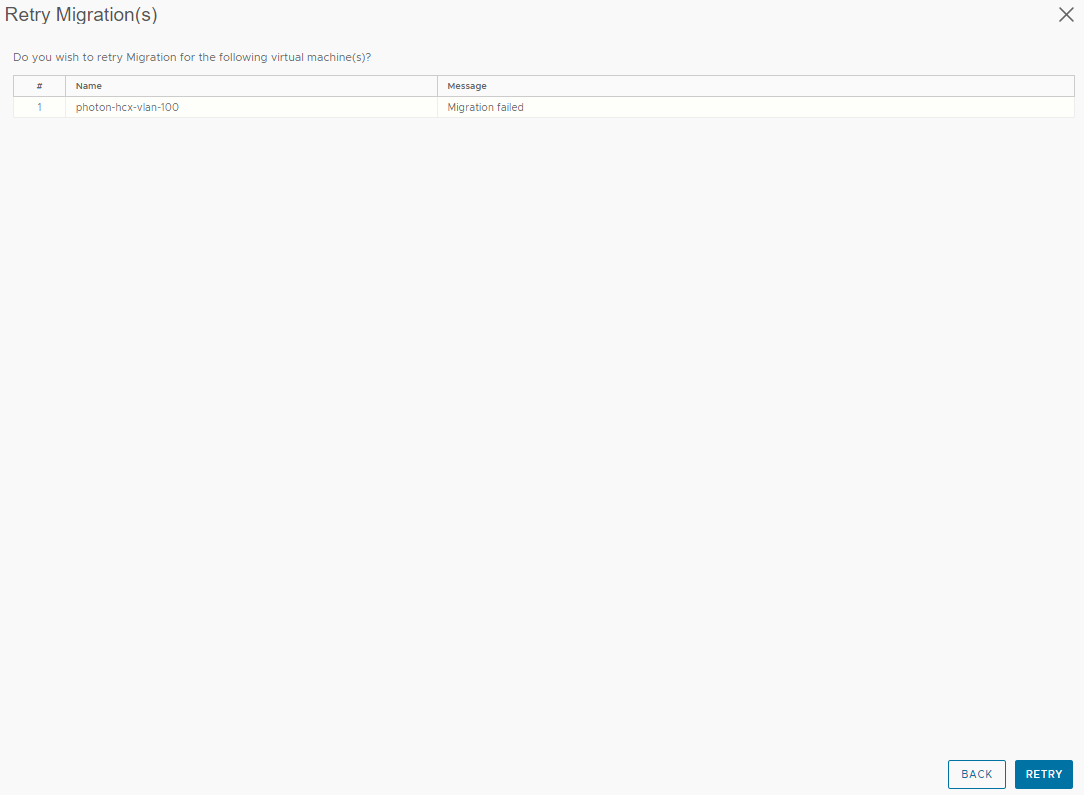
I should caveat at this point, if you were to have experience an issue such as this one in production the VM would already be in place at the cloud site and as the error message states you would look to power this on manually. As I am looking to test the retry option here from HCX in the event of a migration failure, I have manually deleted the VM in the cloud site.
And there we have it, the migration task completed successfully after making use of the retry function.
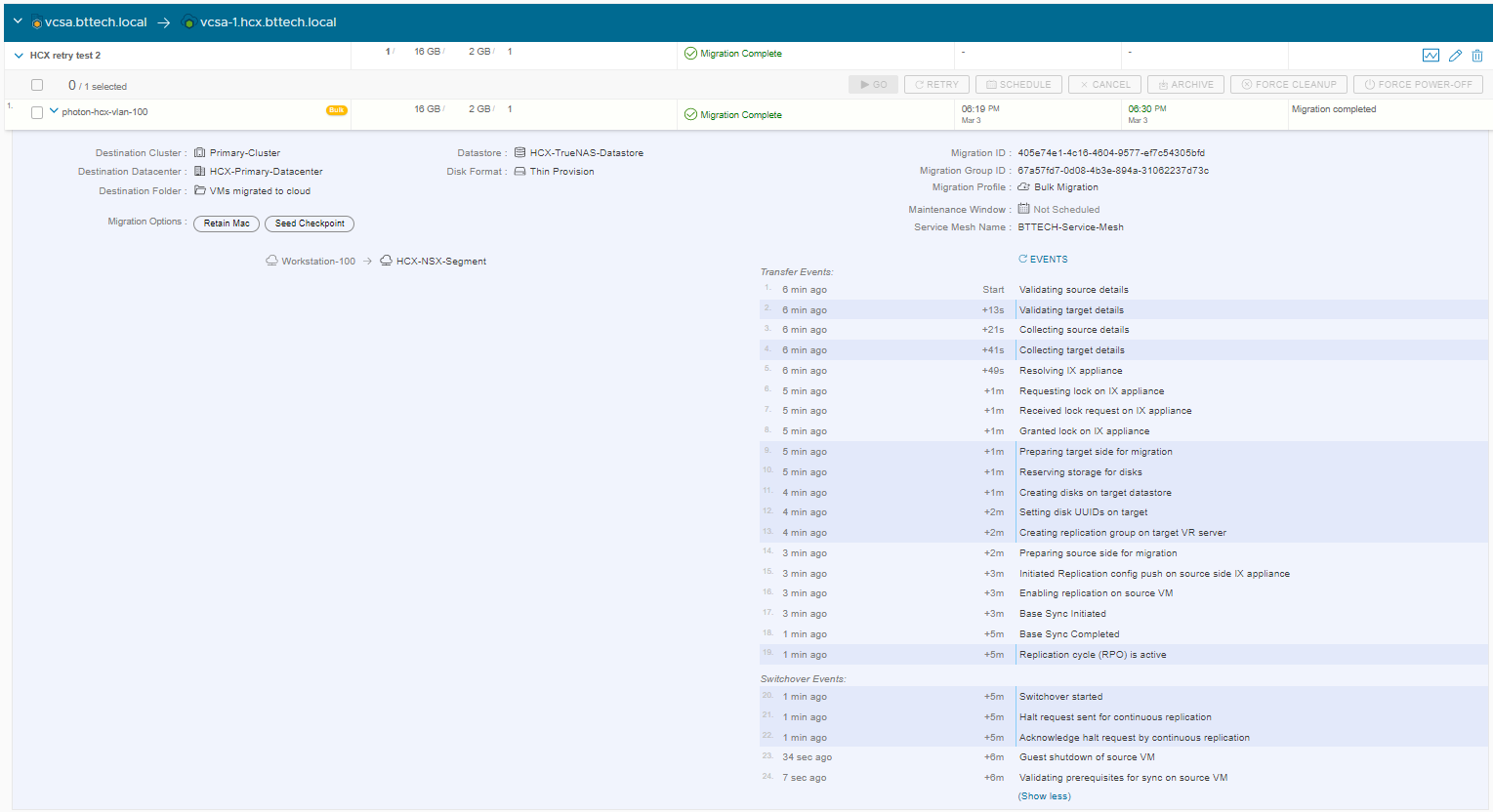
I think what would be great to see here perhaps could be an indication that this task has been retried, perhaps a counter or something along those lines. In summary though, I think this is a great little addition to the HCX functionality.


