
**UPDATE 13/06/22** After the first article was published, I was giving the lab setup some more thought. It just wasn't sitting right with me why I had to create a new VPN to allow the IX appliances to communicate correctly. After all when you run HCX over the internet the IX appliance cannot connect to the IX appliance on-prem via it's private IP address! An update article is now below :), I have left the old content in strikethrough text as reminder to myself, after all I am blogging about my experience more than anything here.
I have been working on increasing my HCX knowledge recently and wanted to be able to build a lab for this that really did simulate that of a real world environment. Well as much of as it as I could of course. My current lab where I test and build HCX utilises a combination of my physical “main” lab if you will and a nested lab that has been built which serves as the the destination. The nested lab was built using one of William Lams invaluable scrips (thank you for these), specifically this one with just a few configuration points to complete in the script I had a nested environment up and running in no time to be used as my HCX destination, dubbed the HCX Cloud.
The destination HCX Cloud sat in a different VLAN to that of the base lab so was sufficient enough to see routing from one environment to another and also simulate the stretching of networks via the Network Extension appliances within the Service Mesh.
I didn’t really satisfy my curiosity though, so I had a thought, I’ll borrow some space from my parents and moving one of my “spare” nodes there to really test this out.
Getting this to work though, wasn’t the easiest of tasks (actually, it was, I over complicated it) – that will teach me for going into building it without giving any thought to it. I prepped the host as a standalone system, ready to serve as a second HCX Cloud to my lab. The physical host is running a VCSA, NSX-T Manager and Edge nodes, HCX Cloud Manager, Windows server that acts as a jump box as well as running DNS and a pfsense appliance that became the answer to my woes, well that’s what I thought. I gave the setup further thought after the first article was posted and realised that I didn’t need this!
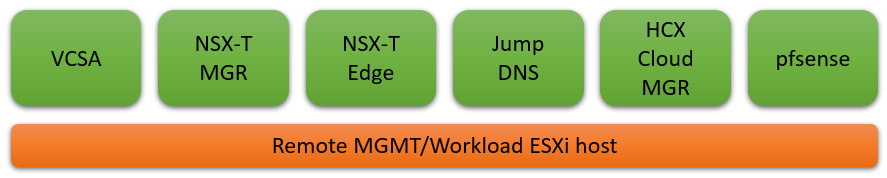
The first issue I had gave no thought to, connectivity to and from the appliances. I had the idea initially that this would all run over the internet, a bit like when running in VMC for example. Well that wasn’t going to happen, with only a single external IP available at the second HCX Cloud and no support for NAT with the HCX traffic flows the below communication would fail.
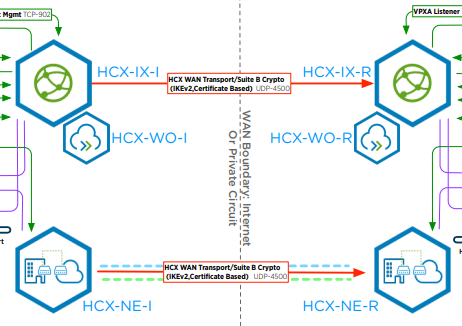
Okay, no problem, I have a VPN from my place to my parents, I’ll pass the HCX uplink traffic through there. I’ll still see increases in latency on the network extensions owing to the internet links between and knowing that I have a VM that is “physically” a few miles away from it’s gateway but still showing a single hop to it, that will satisfy my curiosity. Ah that won’t work, the VPN isn’t configured in a site to site manner and only allows traffic one way although I hadn’t realised this constraint to start. When the service mesh was built, all services reported healthy , I was able to extend a network from my lab over HCX and I was ready to migrate a VM. So this is the point that I made the mistake, of course that will work, as the above diagram shows the source site initiates the connection to the destination. As I also mentioned the Service Mesh was up, all service configured were reporting green and I had extended a network – it was working!
I chose a nice small photon OS VM, as my ISP is Virgin Media I struggle with any form of decent upload speeds so I wanted to have to copy as little data as possible. I kicked off a cold migration, to keep it simple to start with in high hopes, the migration failed.
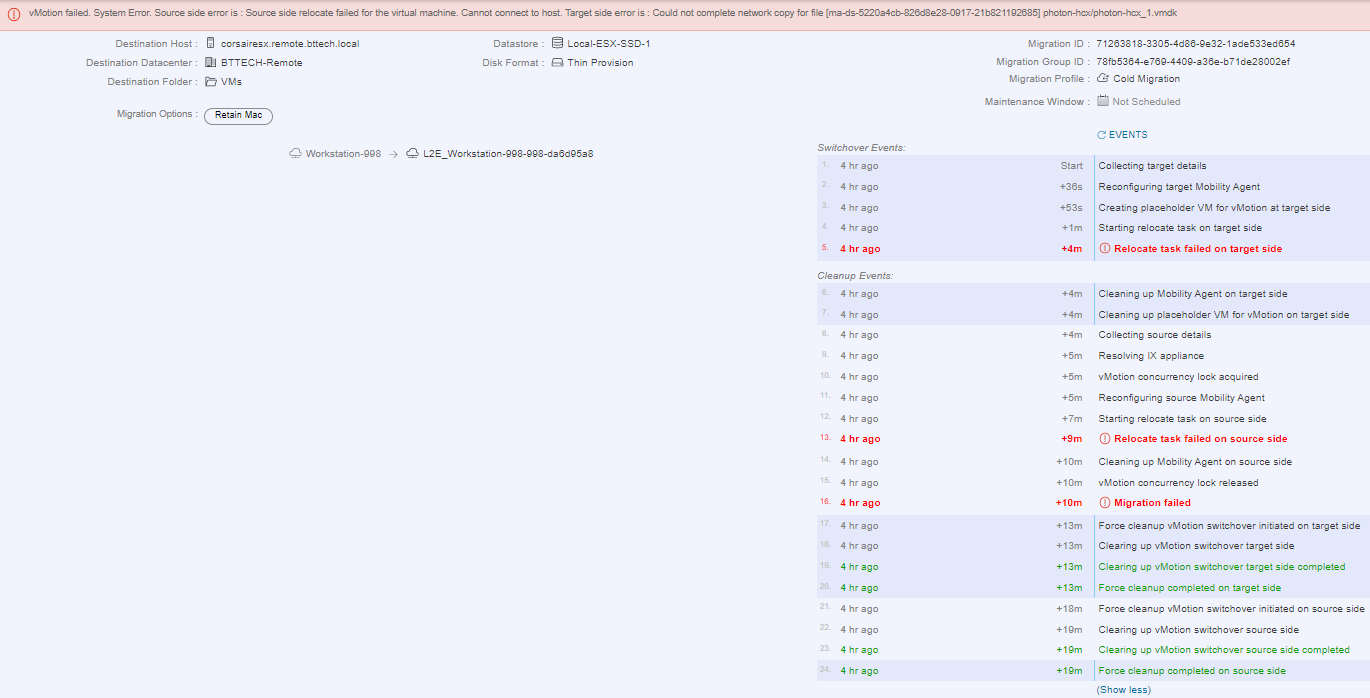
I tried another 2 times to carry out the same migration, well after all this is a lab environment, none of the hardware is supported, the networking between the two locations doesn’t meet production requirements it could have been a blip. Then it dawned on me, the IX and NE appliances on each site would need to be able to communicate with their counter on the apposing site. Well that communication was only possible one way with the current VPN configuration. Right, that’s where I went wrong. I confirmed this buy placing a VM on the extended network in the HCX Cloud and was able to ping another VM on the same subnet in the source site. It turns out it was user error! I had a MTU miss match in the configuration in my VPN configuration providing the connectivity to the HCX Cloud appliances, every day is a school day!
This is where the pfsense appliance in the HCX Cloud site (lab kit at my parents) saved the day. I deployed the appliance with the WAN interface connected to the local network, the same network as all the other lab kit there. Created a new port-group in vCenter, assigned it to the LAN side to be used for the IX and NE uplinks. Once deployed, I configured a site-to-site VPN between the pfsense router at my place and the newly deployed pfsense router in the remote lab. After a little back and fourth with the config I was then able to communicate from the local lab network to the new remote lab network over the VPN, perfect now the appliances would be able to communicate.
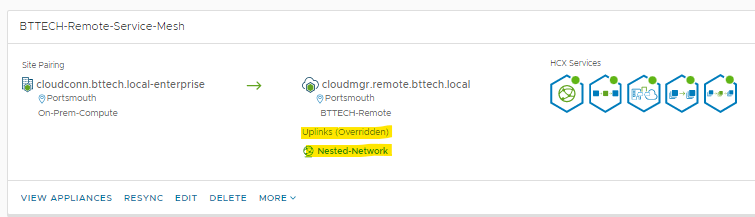
Next step was to create a new network profile on the HCX Cloud Manager system, which I could then specify within the compute profile for the appliance uplinks or override the uplink network profile in the Service Mesh configuration, I chose to do the latter. Editing the Service Mesh and setting the new uplink profile just created.

The Service Mesh now shows that the uplinks on the cloud site/destination have been overridden.
Using the topology output from HCX, I have shown where in the traffic flow the new pfsense appliance sites at the remote site.
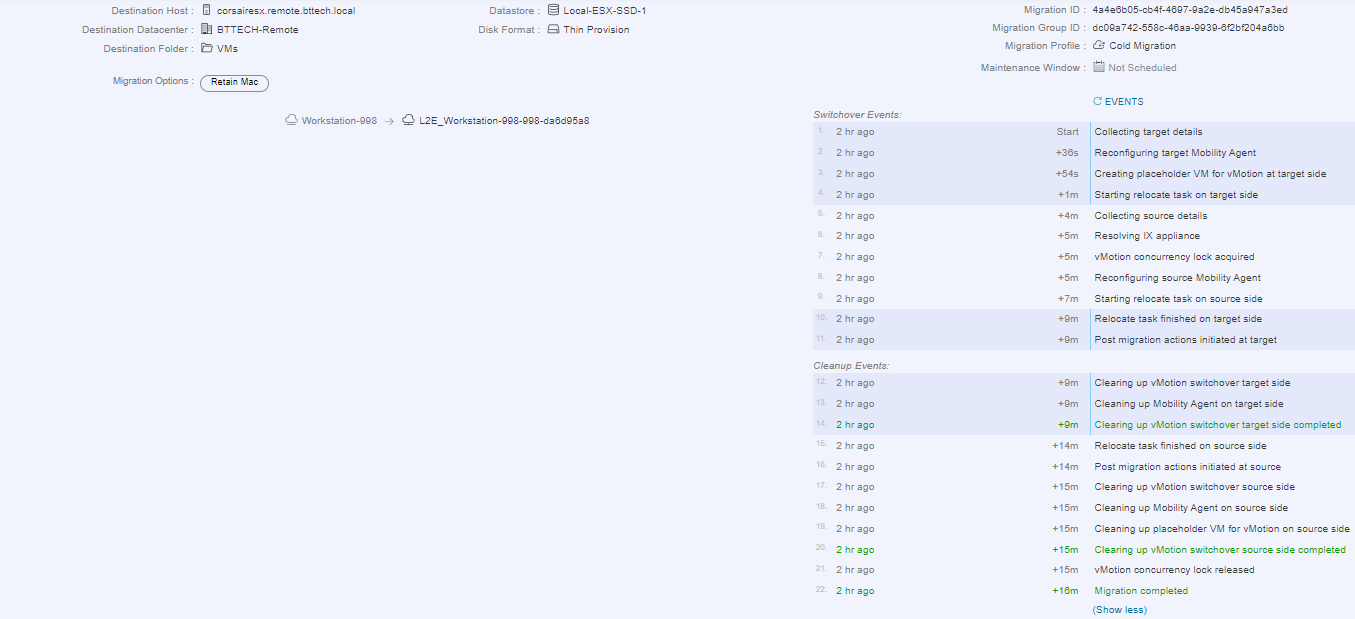
Time to try and migrate that photon VM again, it worked! Without the additional VPN in place as well :).
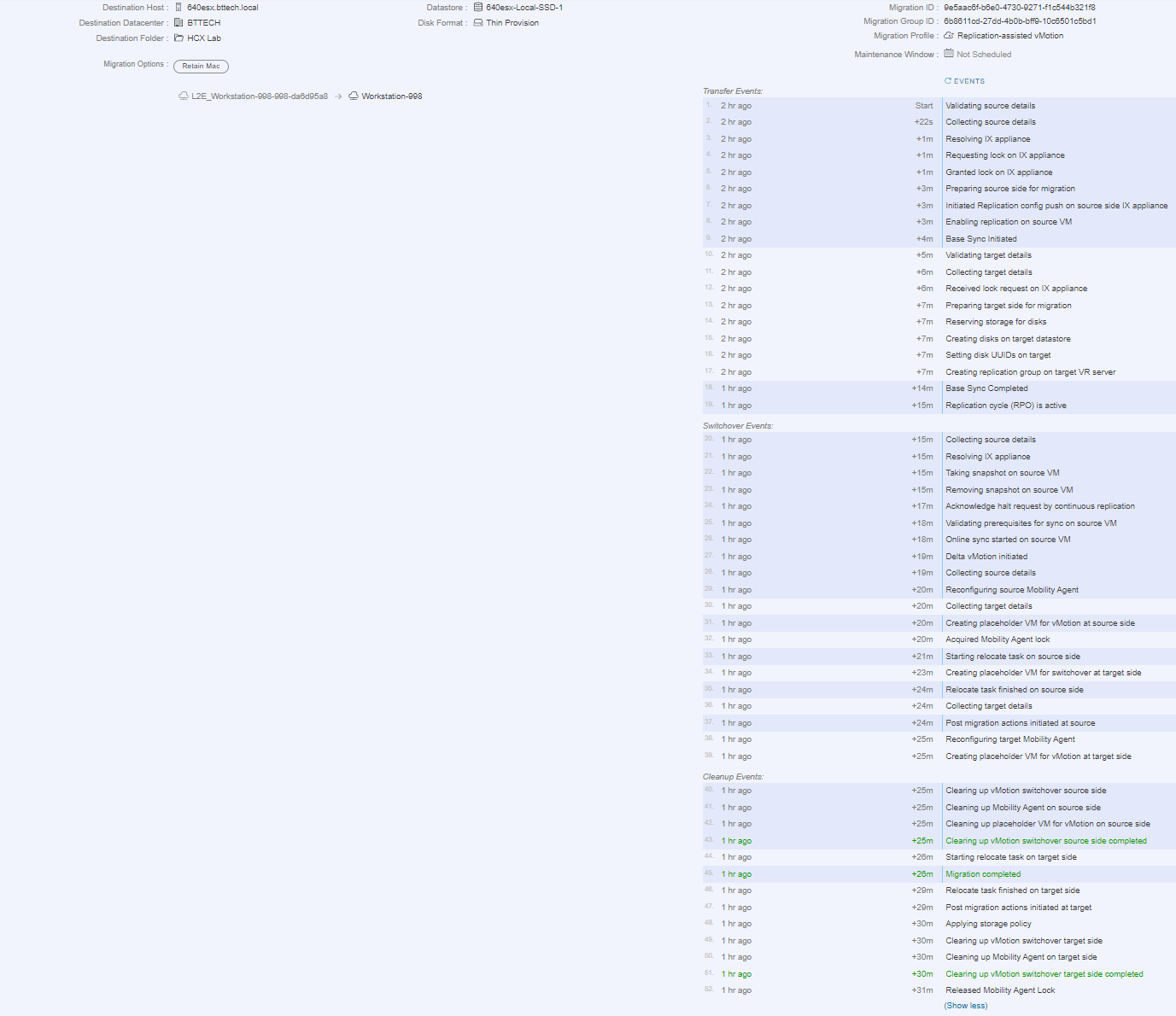
I Powered the VM up, and sure enough the network extension was in place and working. I was able to ping the GW for the extended network and devices on the main lab network, these were being advertised over the new VPN connection as well. I wanted to be 100% sure that I was passing traffic over the network extension, I tested a ping to a device on a different network that wasn’t advertised over VPN connection, meaning it would have to route via the GW in my lab or fail. Great result that worked! In fact the RTT wasn’t that bad neither, using a VM on the local network in the extended network, sending a ping to VM on the remote site I was seeing an average of 50ms RTT.
That gave me one more idea, I wonder, I wonder if I could use RAV (Replication assisted vMotion) to move the VM from the remote lab to the local lab. In theory it should work, but would the lab kit be up to the job. I kicked off the job fulling expecting it to fail, to my surprise though it worked and worked well.
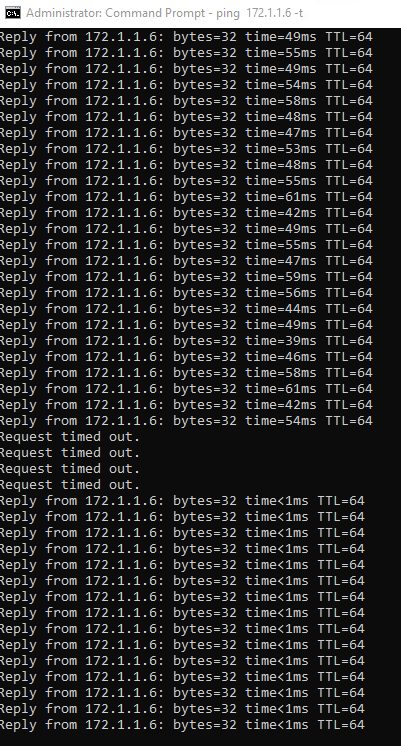
Using a VM on the local subnet, I had a continuous ping running to the photon VM that was being migrated back. Now don’t get me wrong it did take a little while to complete, around 30 minutes but as you can see from the below screenshot the RTT was circa 50ms, there are then a few dropped packets as the VM migrates from the remote site to the local site and then the RTT of the ping is sub 1ms!
Now that my curiosity has been satisfied it’s got me thinking more about the post. There’s not that much technical content in there, not in the sense of configure X, Y and Z to make this happen. It could be worth expanding some more on these areas perhaps, more detailed networking diagrams maybe. I welcome any thoughts on that if anyone would like any element expanded on.



Gabe
Love this Ben! We’re soon adding tooling related to Path MTU within the new Transport Analytics.
Ben Turner
Thank you Gabe :). Upgrading my lab is on the to-do list to look at the Transport Analytics in 4.4